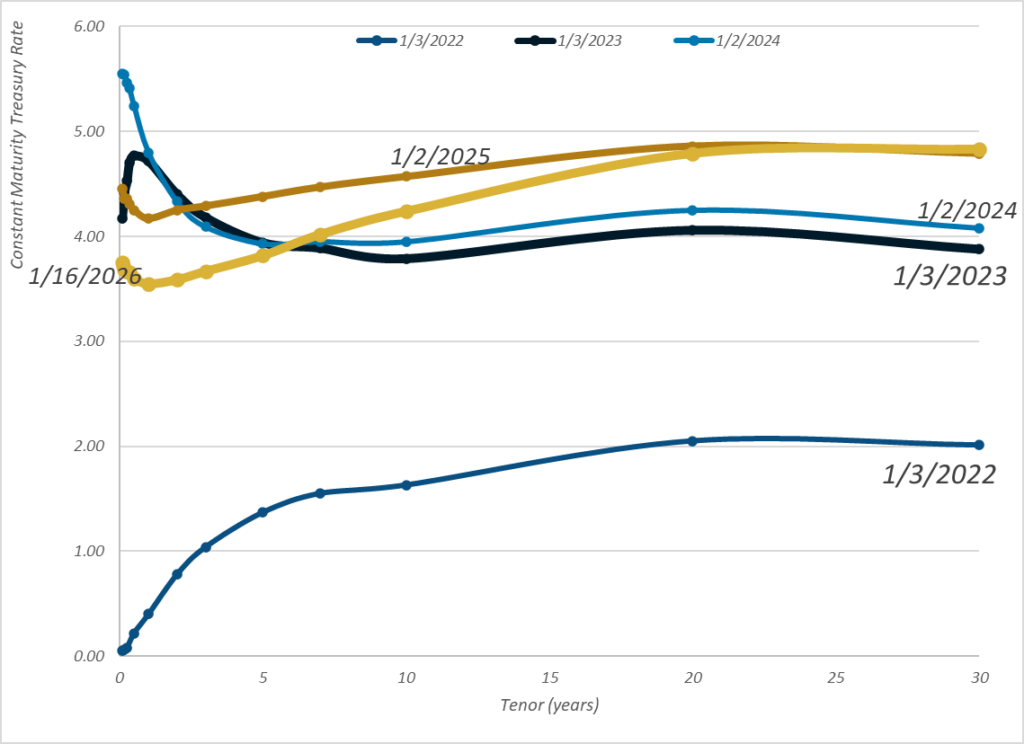
Link: https://actuary.org/wp-content/uploads/2011/09/retirement-monograph-IESA.pdf
Graphic:
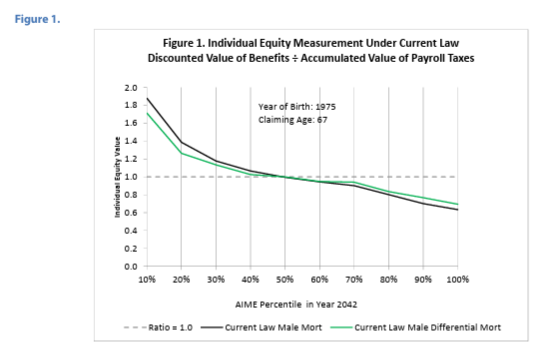
Excerpt:
These three features are sometimes characterized by the terms “universality” and “earned right.” Universality means that Social Security covers nearly all workers, across the entire earnings spectrum and everyone contributes toward those benefits at the same rate. The fact that even the very wealthy receive Social Security helps prevent benefits to the less well off from being stigmatized as welfare payments. Earned right means that a worker’s entitlement to a Social Security benefit derives from the worker’s employment and from the payroll taxes paid on earnings rather than from financial need. Together, the concepts of universality and an earned right to a benefit distinguish the program from needs-based programs such as Medicaid and SNAP (Supplemental Nutrition Assistance Program, formerly known as Food Stamps), thereby contributing to more widespread and enduring public support for Social Security.
….
Both individual equity and social adequacy are essential to the success of Social Security, by sustaining public support, and by providing a minimum level of income for covered workers and eligible family members. The mix of features that make up the program represents a trade-off between the principles of individual equity and social adequacy. The resulting balance has changed as the program has evolved. For example, spouse, survivor, and disability benefits, as well as benefits for non-spouse family members, were added and expanded at various times over Social Security’s history. The last amendment to the Social Security Act that resulted in a material benefit change was adopted in 1983. There is no theoretically correct balance between individual equity and social adequacy in Social Security. The current mix is the product of many legislative compromises that are incorporated into the current version of the Social Security Act.
Author(s): The Social Security Committee, which authored this monograph, includes Sam Gutterman, MAAA, FSA, FCA, FCAS, HonFIA, CERA— Chairperson; Janet Barr, MAAA, ASA; Gordon Enderle, MAAA, FSA; Iris Kazin, MAAA, FSA, FCA, EA; Eric Klieber, MAAA, FSA; Brian Murphy, MAAA, FSA, FCA, EA; John Nylander, MAAA, FSA; Larry Rubin, MAAA, FCA, FSA; Jeffery M. Rykhus, MAAA, FSA; and Joan Weiss, MAAA, FSA.
Publication Date: last updated April 2024, accessed 8 July 2026
Publication Site: American Academy of Actuaries, actuary.org