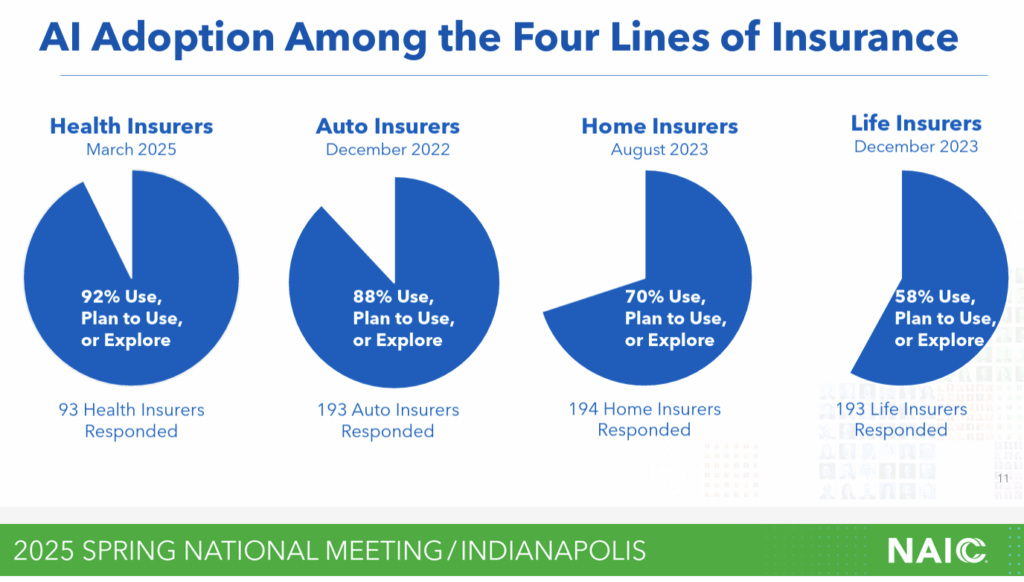
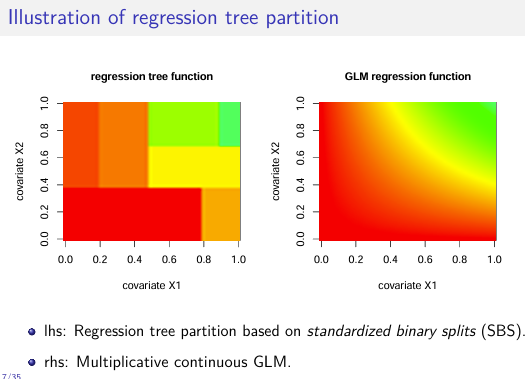
This project aims to empower the actuarial profession with modern machine learning and AI tools. We provide comprehensive teaching materials that consist of lecture notes (technical document) building the theoretical foundation of this initiative. Each chapter of these lecture notes is supported by notebooks and slides which give teaching material, practical guidance and applied examples. Moreover, hands-on exercises in both R and Python are provided in additional notebooks.
Author(s): Mario V. Wüthrich, Ronald Richman, Benjamin Avanzi, Mathias Lindholm, Michael Mayer, Jürg Schelldorfer, Salvatore Scognamiglio
A casualty actuary might be forgiven for thinking that illness and disease are what those “other” actuaries worry about.
Though risk of illness is usually considered the province of the life-health actuary, a session at the 2017 CAS Annual Meeting in Anaheim, California, showed how epidemics can affect property-casualty risks. The session also described how to approach modeling those exposures.
….
Milliman actuary Cody Webb, FCAS, began by demonstrating how big the insurance gap is, particularly in developing nations. He explained that the spectrum of losses ranges from minuscule (loss of a single strand of hair) to catastrophic (sudden, instant death) and can affect a single person or every entity in the universe across eons. But the insurable losses share some traits, Webb said, including:
a large number of similar exposures.
a definite loss, driven by some sort of accident.
the ability to create an affordable premium to reimburse after such a loss.
the ability to accurately quantify the amount of loss sustained. This is the most important shared trait.
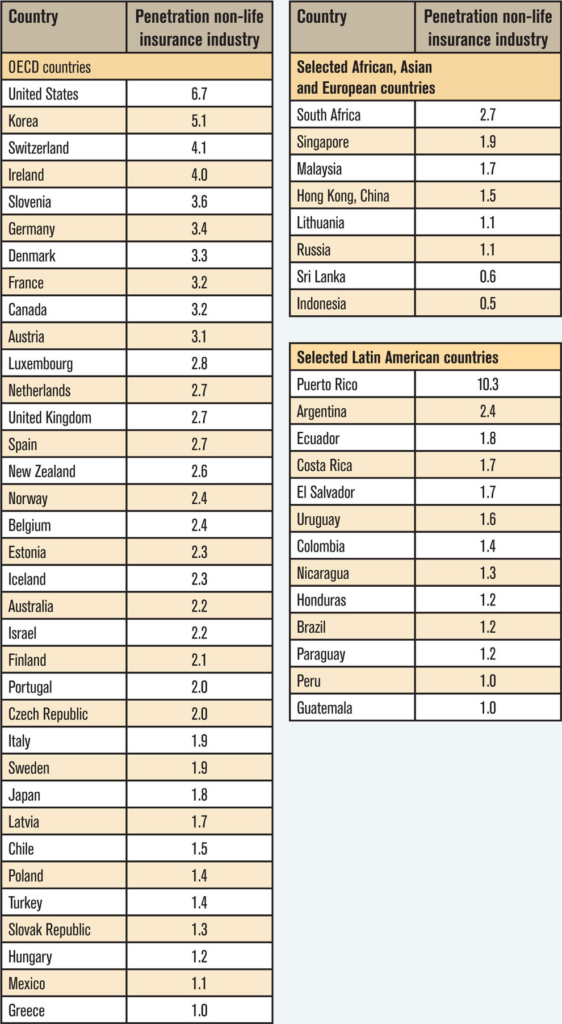
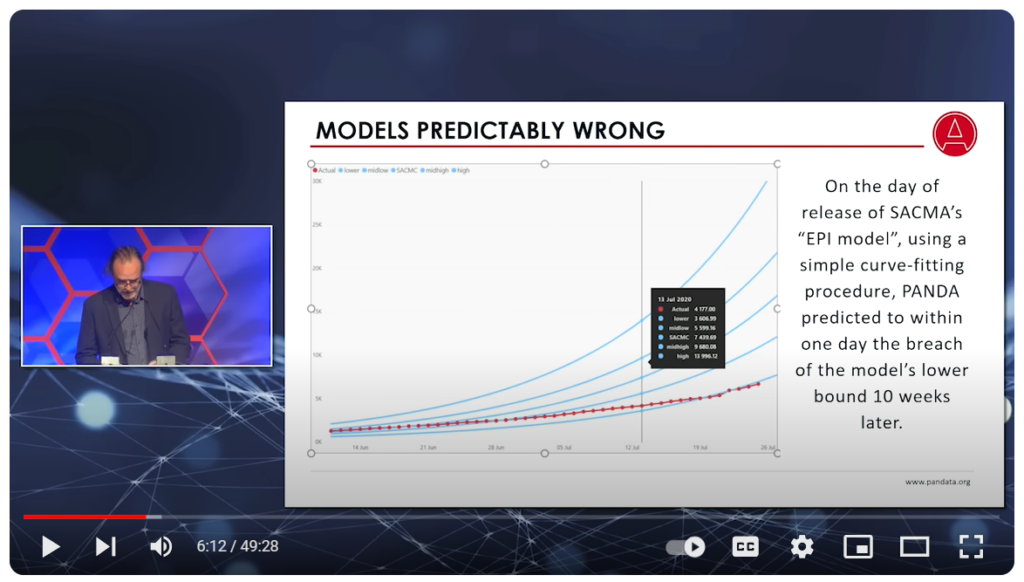
In showing a chart of property-casualty insurance as a percentage of GDP — with the wealthier countries better insured than others — Webb noted that insurance companies need to “quantify and develop products that meet all criteria of insurability.” (See chart below.)
Author(s): James P. Lynch
Publication Date: 16 Jan 2018
Publication Site: Actuarial Review, Casualty Actuarial Society
This paper describes the use and professionalism considerations for actuaries using generative artificial intelligence (GenAI) to provide actuarial services. GenAI generates text, quantitative, or image content based on training data, typically using a large language model (LLM). Examples of GenAI deployments include Open AI GPT, Google Gemini, Claude, and Meta. GenAI transforms information acquired from training data into entirely new content. In contrast, predictive AI models analyze historical quantitative data to forecast future outcomes, functioning like traditional predictive statistical models.
Actuaries have a wide range of understanding of AI. We assume the reader is broadly familiar with AI and AI model capabilities, but not necessarily a designer or expert user. In this paper, the terms “GenAI,” “AI,” “AI model(s),” and “AI tool(s)” are used interchangeably. This paper covers the professionalism fundamentals of using GenAI and only briefly discusses designing, building, and customizing GenAI systems. This paper focuses on actuaries using GenAI to support actuarial conclusions, not on minor incidental use of AI that duplicates the function of tools such as plug-ins, co-pilots, spreadsheets, internet search engines, or writing aids.
GenAI is a recent development, but the actuarial professionalism framework helps actuaries use GenAI appropriately: the Code of Professional Conduct, the Qualification Standards for Actuaries Issuing Statements of Actuarial Opinion in the United States (USQS), and the actuarial standards of practice (ASOPs). Although ASOP No. 23, Data Quality; No. 41, Actuarial Communications; and No. 56, Modeling, were developed before GenAI was widely available, each applies in situations when GenAI may now be used. The following discussion comments on these topics, focusing extensively on the application of ASOP No. 56, which provides guidance for actuaries when they are designing, developing, selecting, modifying, using, reviewing, or evaluating models. GenAI is a model; thus ASOP No. 56 applies.
The paper explores use cases and addresses conventional applications, including quantitative and qualitative analysis, as of mid-2024, rather than anticipating novel uses or combinations of applications. AI tools change quickly, so the paper focuses on principles rather than the technology. The scope of this paper does not include explaining how AI models are structured or function, nor does it offer specific guidelines on AI tools or use by the actuary in professional settings. Given the rapid rate of change within this space, the paper makes no predictions about the rapidly evolving technology, nor does it speculate on future challenges to professionalism.
Author(s): Committee on Professional Responsibility of the American Academy of Actuaries
Committee on Professional Responsibility Geoffrey C. Sandler, Chairperson Brian Donovan Richard Goehring Laura Maxwell Shawn Parks Matthew Wininger Kathleen Wong Yukki Yeung Paul Zeisler Melissa Zrelack
Artificial Intelligence Task Force Prem Boinpally Laura Maxwell Shawn Parks Fei Wang Matt Wininger Kathy Wong Yukki Yeung
Here are several examples of ChatBots and other AI applications for actuaries to try.
Answers that you might get from a general AI LLM such as ChatGPT may or may not correctly represent the latest thinking in actuarial science. These chatBots make an effort to educate the LLM with actuarial or other pertinent literature so that you can get better informed answers.
But, you need to be a critical user. Please be careful with the responses that you get from these ChatBots and let us know if you find any issues. This is still early days for the use of AI in actuarial practice and we need to learn from our experiences and move forward.
Note from meep: there are multiple Apps/Bots linked from the main site.
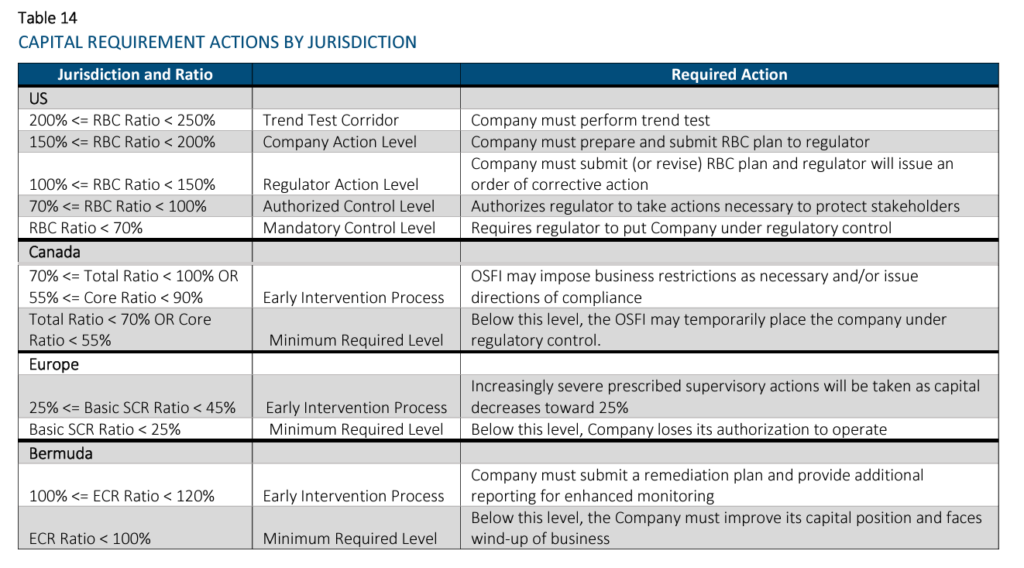
The purpose of this paper is to introduce the concept of capital and key related terms, as well as to compare and contrast four key regulatory capital regimes. Not only is each regime’s methodology explained with key terms defined and formulas provided, but illustrative applications of each approach are provided via an example with a baseline scenario. Comparison among these capital regimes is also provided using this same model with two alternative scenarios.
The four regulatory required capital approaches discussed in this paper are National Association of Insurance Commissioners’ (NAIC) Risk-Based Capital (RBC; the United States), Life Insurer Capital Adequacy Test (LICAT; Canada), Solvency II (European Union), and the Bermuda Insurance Solvency (BIS) Framework which describes the Bermuda Solvency Capital Requirement (BSCR). These terms may be used interchangeably. These standards apply to a large portion of the global life insurance market and were chosen to give the reader a better understanding of how required capital varies by jurisdiction, and the impact of the measurement method on life insurance company capital.
All of these approaches are similar in that they identify key risks for which capital should be held (e.g., asset default and market risks, insurance risks, etc.). However, they differ in significant ways too, including their defined risk taxonomy and risk diversification / aggregation methodologies, as well as required minimum capital thresholds and corresponding implications. Another key difference is that the US’s RBC methodology is largely factor-based, while the other methodologies are model-based approaches. For the model-based approaches, Solvency II and BIS allow for the use of internal models when certain conditions are satisfied. Another difference is that the RBC methodology is largely derived using book values, while the others use economic-based measurements.
As mentioned above, this paper provides a model that calculates the capital requirements for each jurisdiction. The model is used to compare regulatory solvency capital using identical portfolios for both assets and liabilities. For simplicity, we have assumed that all liabilities originated in the same jurisdiction as the calculation. As the objective of the model is to illustrate required capital calculation methodology differences, a number of modeling simplifications were employed and detailed later in the paper. The model considers two products – term insurance and payout annuities, approximately equally weighted in terms of reserves. The assets consist of two non-callable bonds of differing durations, mortgages, real estate, and equities. Two alternative scenarios have been considered, one where the company invests in riskier assets than assumed in the base case and one where the liability mix is more heavily weighted to annuities as compared to the base case.
Author(s): Ben Leiser, FSA, MAAA; Janine Bender, ASA, MAAA; Brian Kaul
The Term Guy’s hobby is collecting antique insurance books. Here we’ve scanned many of our out of copyright books for your enjoyment and perhaps research purposes. Stay tuned, more books coming as I have time to scan them!
We have extracted table data from many of these books and made the information available as excel spreadsheets. In the download of spreadsheets we have also included a high def image of each of the pages containing the tables. The image filename for each page and the excel spreadsheet have the same name, i.e. image0001.jpg.xlxs contains table data from image0001.jpg. You may download and use the data unrestricted, but we would ask that you consider giving us a link from your website so that others can find this information as well.
Whoever you decide to vote for, please do take the time to engage with the election process, consider what each candidate can contribute to move the profession forwards, and whether you want an active council or a passive council: make your vote count for the sake of your profession.
Although employer-provided retirement plans are a relatively recent phenomenon in the private sector, dating from the late nineteenth century, public sector plans go back much further in history. From the Roman Empire to the rise of the early-modern nation state, rulers and legislatures have provided pensions for the workers who administered public programs. Military pensions, in particular, have a long history, and they have often been used as a key element to attract, retain, and motivate military personnel. In the United States, pensions for disabled and retired military personnel predate the signing of the U.S. Constitution.
Like military pensions, pensions for loyal civil servants date back centuries. Prior to the nineteenth century, however, these pensions were typically handed out on a case-by-case basis; except for the military, there were few if any retirement plans or systems with well-defined rules for qualification, contributions, funding, and so forth. Most European countries maintained some type of formal pension system for their public sector workers by the late nineteenth century. Although a few U.S. municipalities offered plans prior to 1900, most public sector workers were not offered pensions until the first decades of the twentieth century. Teachers, firefighters, and police officers were typically the first non-military workers to receive a retirement plan as part of their compensation.
By 1930, pension coverage in the public sector was relatively widespread in the United States, with all federal workers being covered by a pension and an increasing share of state and local employees included in pension plans. In contrast, pension coverage in the private sector during the first three decades of the twentieth century remained very low, perhaps as low as 10 to 12 percent of the labor force (Clark, Craig, and Wilson 2003). Even today, pension coverage is much higher in the public sector than it is in the private sector. Over 90 percent of public sector workers are covered by an employer-provided pension plan, whereas only about half of the private sector work force is covered (Employee Benefit Research Institute 1997).
Author(s): Lee A. Craig, North Carolina State University
Publication Date: 16 March 2003, accessed 8 Oct 2022
Professionalization leads us to an interesting dilemma. Actuarial culture and, for that matter, organizational culture got insurance companies to where they are today. If the culture were not moderately successful, then the company would not still exist. But this is where Prospect theory emerges from the shadows. It is human nature not to want to lose the culture that enabled your success. Many people nonetheless thirst for the gains earned by moving in a new direction. Risk aversion further reinforces the stickiness of culture, especially for risk-averse professions and industries. Drawing from author Tony Robbins, you cannot become who you want to be by staying who you currently are. Our professionalization, coupled with our risk aversion, creates a double whammy. Practices appropriate to prior eras have a propensity to be locked in place. Oh, but it gets worse!
By the nature of transformation and modernization, knowledge and know-how are embedded in the current people, processes and systems. The knowledge and know-how must be migrated from the prior technology to modern technology. Just like your computer’s hard drive gets fragmented, so too do firms’ expertise as people change focus, move jobs or leave companies. The long-dated nature of our promises can severely exacerbate the issue. Human knowledge and know-how are not very compressible, unlike biological seeds and eggs. In a time-consuming defragmenting exercise, information, knowledge and know-how must be painstakingly moved, relearned and adapted for the new system. This transformation requires new practices, further exacerbating the shock to the culture. Oh, but it gets even worse!
The transformation process requires existing teams to change, recombine or communicate in new ways. This means their cultures will potentially clash. Lack of trust and bureaucracy are the most significant frictions to collaboration among networks. The direct evidence of this is when project managers vent that teams x, y and z cannot seem to work together. It is because they do not have a reference system to know how to work together.
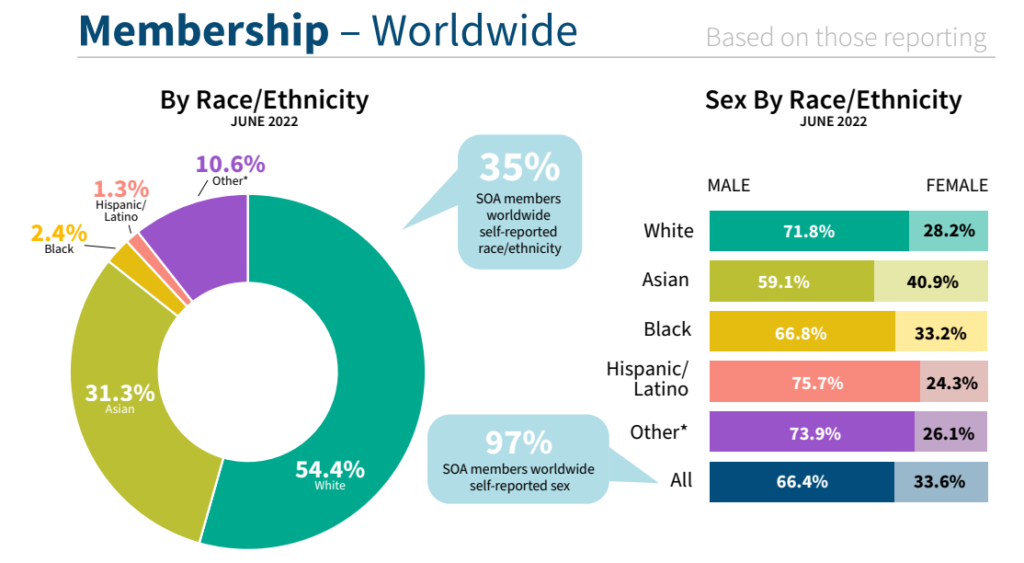
The Society of Actuaries (SOA) leadership and staff work closely with the Diversity, Equity, and Inclusion Committee (DEIC) to support the journey to increase diversity in membership and in the actuarial profession, as part of the SOA’s Long-Term Growth Strategy.
We strive for transparency and accountability in our DEI efforts and are committed to sharing our demographic data and long-term goals to support our pledge and responsibility. We have collected member voluntary demographic data since 2015. With this data, we present an infographic for the pathway from aspiring actuaries to members with ASA or FSA designations.