Link: https://matthewstrom.com/writing/how-to-pick-the-least-wrong-colors/
Graphic:
Excerpt:
Stripe’s dashboards use graphs to visualize data. While the color palettes we use are certainly passable, the team is always trying to improve them. A colleague was working on creating updated color palettes, and we discussed the challenges he was working through. The problem boiled down to this: how do I pick nice-looking colors that cover a broad set of use cases for categorical data while meeting accessibility goals?
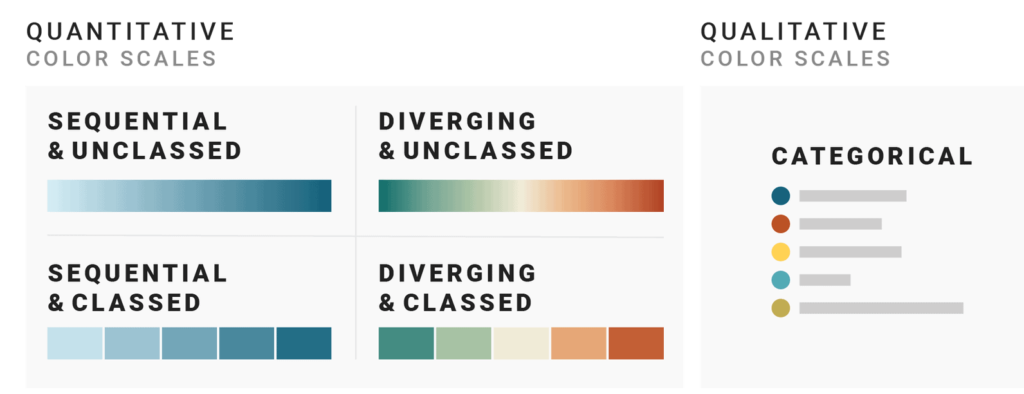
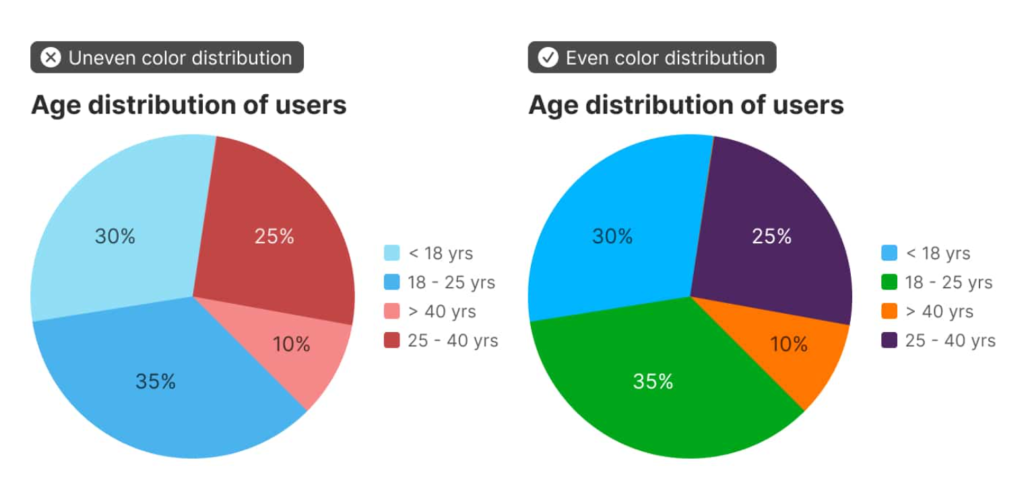
The domain of this problem is categorical data — data that can be compared by grouping it into two or more sets. In Stripe’s case, we’re often comparing payments from different sources, comparing the volume of payments between multiple time periods, or breaking down revenue by product.
The criteria for success are threefold:
- The colors should look nice. In my case, they need to be similar to Stripe’s brand colors.
- The colors should cover a broad set of use cases. In short, I need lots of colors in case I have lots of categories.
- The colors should meet accessibility goals. WCAG 2.2 dictates that non-text elements like chart bars or lines should have a color contrast ratio of at least 3:1 with adjacent colors.
Author(s): Matthew Ström
Publication Date: 31 May 2022
Publication Site: Matthew Ström