Link: https://static.berkeleyearth.org/papers/Results-Paper-Berkeley-Earth.pdf
Graphic:
Abstract:
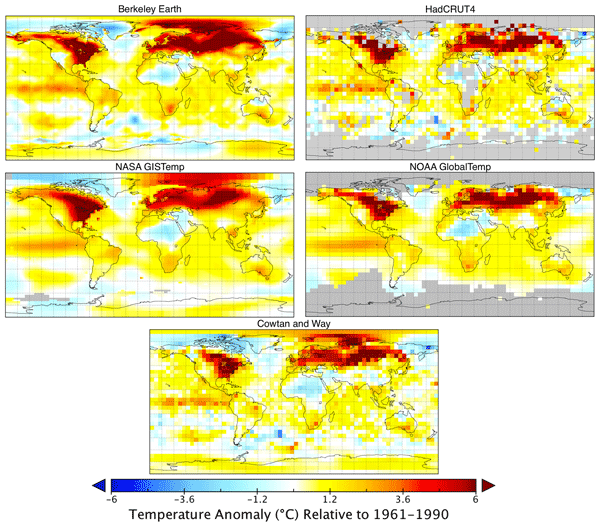
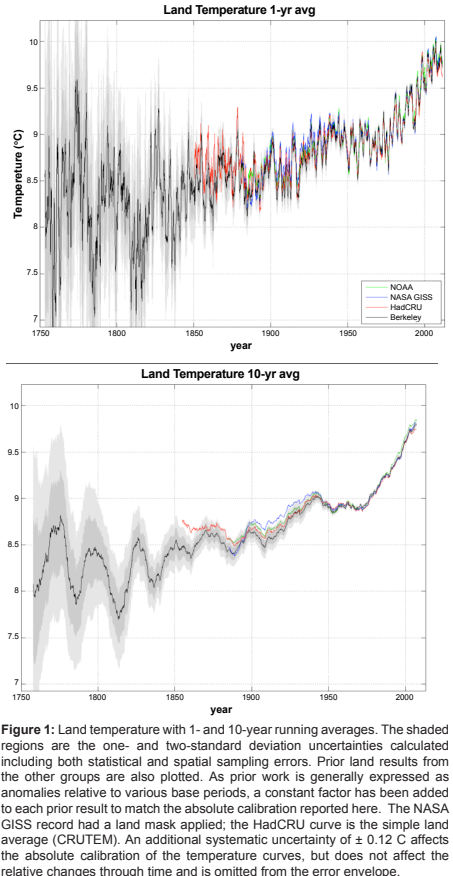
We report an estimate of the Earth’s average land surface temperature for the period 1753 to 2011. To address issues of potential station selection bias, we used a larger sampling of stations than had prior studies. For the period post 1880, our estimate is similar to those previously reported by other groups,
although we report smaller uncertainties. The land temperature rise from the 1950s decade to the 2000s decade is 0.90 ± 0.05°C (95% confidence). Both maximum and minimum temperatures have increased during the last century. Diurnal variations decreased from 1900 to 1987 and then increased; this increase is significant but not understood. The period of 1753 to 1850 is marked by sudden drops in land surface temperature that are coincident with known volcanism; the response function is approximately
1.5 ± 0.5°C per 100 Tg of atmospheric sulfate. This volcanism, combined with a simple proxy for anthropogenic effects (logarithm of the CO2 addition of a solar forcing term. Thus, for this very simple model, solar forcing does not appear to contribute to the observed global warming of the past 250 years; the entire change can be modeled by a sum of volcanism and a single anthropogenic proxy. The residual variations include interannual and multi-decadal variability very similar to that of the Atlantic Multidecadal Oscillation (AMO).
Keywords: Global warming; Kriging; Atlantic multidecadal oscillation;
Amo; Volcanism; Climate change; Earth surface temperature; Diurnal
variability
Author(s):
Robert Rohde1
, Richard A. Muller1,2,3
*, Robert Jacobsen2,3
,
Elizabeth Muller1
, Saul Perlmutter2,3
, Arthur Rosenfeld2,3
,
Jonathan Wurtele2,3
, Donald Groom3
and Charlotte Wickham4
Citation:
Rohde et al., Geoinfor Geostat: An Overview 2013, 1:1
http://dx.doi.org/10.4172/2327-4581.1000101
Publication Date: 2013
Publication Site: Geoinformatics & Geostatistics: An Overview