In August [2022], Birny Birnbaum, the executive director of the Center for Economic Justice, asked the [NAIC] Market Regulation committee to train analysts to detect “dark patterns” and to define dark patterns as an unfair and deceptive trade practice.
The term “dark patterns” refers to techniques an online service can use to get consumers to do things they would otherwise not do, according to draft August meeting notes included in the committee’s fall national meeting packet.
Dark pattern techniques include nagging; efforts to keep users from understanding and comparing prices; obscuring important information; and the “roach motel” strategy, which makes signing up for an online service much easier than canceling it.
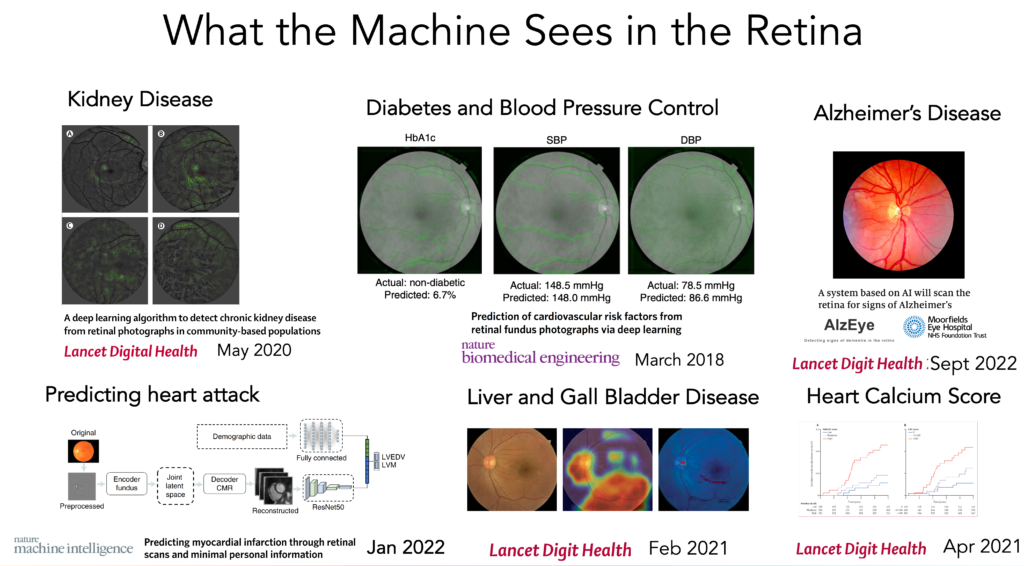
Today’s report on AI of retinal vessel images to help predict the risk of heart attack and stroke, from over 65,000 UK Biobank participants, reinforces a growing body of evidence that deep neural networks can be trained to “interpret” medical images far beyond what was anticipated. Add that finding to last week’s multinational study of deep learning of retinal photos to detect Alzheimer’s disease with good accuracy. In this post I am going to briefly review what has already been gleaned from 2 classic medical images—the retina and the electrocardiogram (ECG)—as representative for the exciting capability of machine vision to “see” well beyond human limits. Obviously, machines aren’t really seeing or interpreting and don’t have eyes in the human sense, but they sure can be trained from hundreds of thousand (or millions) of images to come up with outputs that are extraordinary. I hope when you’ve read this you’ll agree this is a particularly striking advance, which has not yet been actualized in medical practice, but has enormous potential.
Author(s): Eric Topol
Publication Date: 4 Oct 2022
Publication Site: Eric Topol’s substack, Ground Truths
Unfortunately, fraud is rampant in the insurance industry. Property and casualty insurance alone loses about $30 billion to fraud every year, and fraud occurs in nearly 10% of all P&C losses. ML can mitigate this issue by identifying potential claim situations early in the process. Flagging early allows insurers to investigate and correctly identify a fraudulent claim.
5. Claims processing
Claims processing is notoriously arduous and time-consuming. ML technology is a tool to reduce processing costs and time, from the initial claim submission to reviewing coverages. Moreover, ML supports a great customer experience because it allows the insured to check the status of their claim without having to reach out to their broker/adjuster.
Some ML algorithms (e.g., random forests) work very nicely with missing data. No data cleaning is required when using these algorithms. In addition to not breaking down amid missing data, these algorithms use the fact of “missingness” as a feature to predict with. This compensates for when the missing points are not randomly missing.
Or, rather than dodge the problem, although that might be the best approach, you can impute the missing values and work from there. Here, very simple ML algorithms that look for the nearest data point (K-Nearest Neighbors) and infer its value work well. Simplicity here can be optimal because the modeling in data cleaning should not be mixed with the modeling in forecasting.
There are also remedies for missing data in time series. The challenge of time series data is that relationships exist, not just between variables, but between variables and their preceding states. And, from the point of view of a historical data point, relationships exist with the future states of the variables.
For the sake of predicting missing values, a data set can be augmented by including lagged values and negative-lagged values (i.e., future values). This, now-wider, augmented data set will have correlated predictors. The regularization trick can be used to forecast missing points with the available data. And, a strategy of repeatedly sampling, forecasting, and then averaging the forecasts can be used. Or, a similar turnkey approach is to use principal component analysis (PCA) following a similar strategy where a meta-algorithm will repeatedly impute, project, and refit until the imputed points stop changing. This is easier said than done, but it is doable.
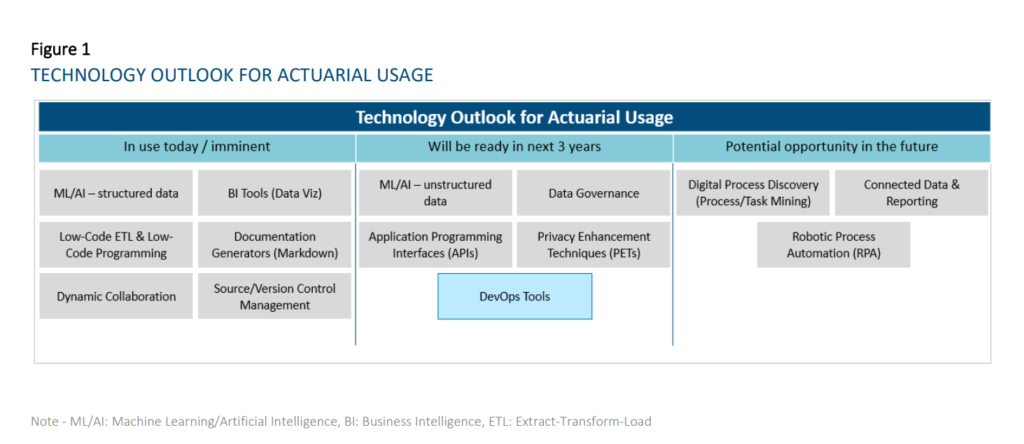
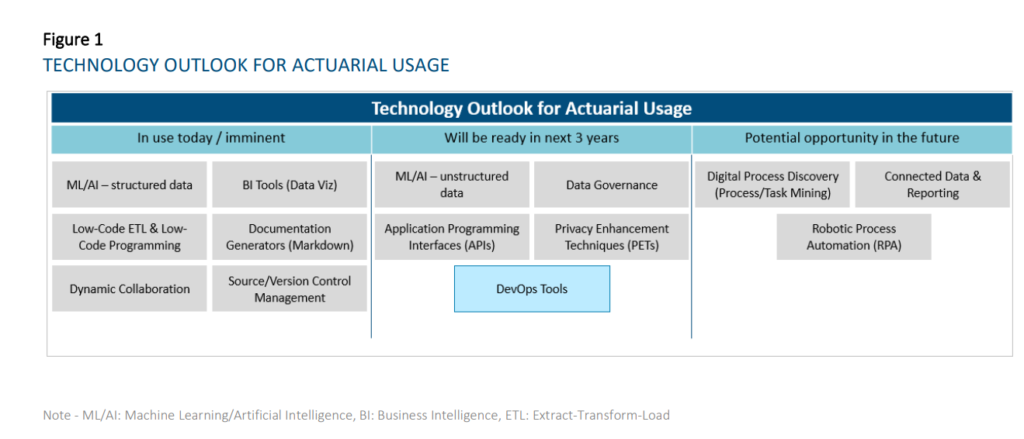
This research evaluates the current state and future outlook of emerging technologies on the actuarial profession over a three-year horizon. For the purpose of this report, a technology is considered to be a practical application of knowledge (as opposed to a specific vendor) and is considered emerging when the use of the particular technology is not already widespread across the actuarial profession. This report looks to evaluate prospective tools that actuaries can use across all aspects and domains of work spanning Life and Annuities, Health, P&C, and Pensions in relation to insurance risk. We researched and grouped similar technologies together for ease of reading and understanding. As a result, we identified the six following technology groups:
Machine Learning and Artificial Intelligence
Business Intelligence Tools and Report Generators
Extract-Transform-Load (ETL) / Data Integration and Low-Code Automation Platforms
Collaboration and Connected Data
Data Governance and Sharing
Digital Process Discovery (Process Mining / Task Mining)
Author(s):
Nicole Cervi, Deloitte Arthur da Silva, FSA, ACIA, Deloitte Paul Downes, FIA, FCIA, Deloitte Marwah Khalid, Deloitte Chenyi Liu, Deloitte Prakash Rajgopal, Deloitte Jean-Yves Rioux, FSA, CERA, FCIA, Deloitte Thomas Smith, Deloitte Yvonne Zhang, FSA, FCIA, Deloitte
Publication Date: October 2021
Publication Site: Society of Actuaries, SOA Research Institute
Technologies that have reached widespread adoption today: o Dynamic Collaboration Tools – e.g., Microsoft Teams, Slack, Miro – Most companies are now using this type of technology. Some are using the different functionalities (e.g., digital whiteboarding, project management tools, etc.) more fully than others at this time. • Technologies that are reaching early majority adoption today: o Business Intelligence Tools (Data Visualization component) – e.g., Tableau, Power BI — Most respondents have started their journey in using these tools, with many having implemented solutions. While a few respondents are lagging in its adoption, some companies have scaled applications of this technology to all actuaries. BI tools will change and accelerate the way actuaries diagnose results, understand results, and communicate insights to stakeholders. o ML/AI on structured data – e.g., R, Python – Most respondents have started their journey in using these techniques, but the level of maturity varies widely. The average maturity is beyond the piloting phase amongst our respondents. These are used for a wide range of applications in actuarial functions, including pricing business, modeling demand, performing experience studies, predicting lapses to support sales and marketing, producing individual claims reserves in P&C, supporting accelerated underwriting and portfolio scoring on inforce blocks. o Documentation Generators (Markdown) – e.g., R Markdown, Sphinx – Many respondents have started using these tools, but maturity level varies widely. The average maturity for those who have started amongst our respondents is beyond the piloting phase. As the use of R/Python becomes more prolific amongst actuaries, the ability to simultaneously generate documentation and reports for developed applications and processes will increase in importance. o Low-Code ETL and Low-Code Programming — e.g., Alteryx, Azure Data Factory – Amongst respondents who provided responses, most have started their journey in using these tools, but the level of maturity varies widely. The average maturity is beyond the piloting phase with our respondents. Low-code ETL tools will be useful where traditional ETL tools requiring IT support are not sufficient for business needs (e.g., too difficult to learn quickly for users or reviewers, ad-hoc processes) or where IT is not able to provision views of data quickly enough. o Source Control Management – e.g., Git, SVN – A sizeable proportion of the respondents are currently using these technologies. Amongst these respondents, solutions have already been implemented. These technologies will become more important in the context of maintaining code quality for programming-based models and tools such as those developed in R/Python. The value of the technology will be further enhanced with the adoption of DevOps practices and tools, which blur the lines between Development and Operations teams to accelerate the deployment of applications/programs
Author(s):
Nicole Cervi, Deloitte Arthur da Silva, FSA, ACIA, Deloitte Paul Downes, FIA, FCIA, Deloitte Marwah Khalid, Deloitte Chenyi Liu, Deloitte Prakash Rajgopal, Deloitte Jean-Yves Rioux, FSA, CERA, FCIA, Deloitte Thomas Smith, Deloitte Yvonne Zhang, FSA, FCIA, Deloitte
Machine learning has great potential for improving products, processes and research. But computers usually do not explain their predictions which is a barrier to the adoption of machine learning. This book is about making machine learning models and their decisions interpretable.
After exploring the concepts of interpretability, you will learn about simple, interpretable models such as decision trees, decision rules and linear regression. Later chapters focus on general model-agnostic methods for interpreting black box models like feature importance and accumulated local effects and explaining individual predictions with Shapley values and LIME.
All interpretation methods are explained in depth and discussed critically. How do they work under the hood? What are their strengths and weaknesses? How can their outputs be interpreted? This book will enable you to select and correctly apply the interpretation method that is most suitable for your machine learning project.
In machine learning, there has been a trade-off between model complexity and model performance. Complex machine learning models e.g. deep learning (that perform better than interpretable models e.g. linear regression) have been treated as black boxes. Research paper by Ribiero et al (2016) titled “Why Should I Trust You” aptly encapsulates the issue with ML black boxes. Model interpretability is a growing field of research. Please read here for the importance of machine interpretability. This blog discusses the idea behind LIME and SHAP.
In the midst of the uncertainty, Epic, a private electronic health record giant and a key purveyor of American health data, accelerated the deployment of a clinical prediction tool called the Deterioration Index. Built with a type of artificial intelligence called machine learning and in use at some hospitals prior to the pandemic, the index is designed to help physicians decide when to move a patient into or out of intensive care, and is influenced by factors like breathing rate and blood potassium level. Epic had been tinkering with the index for years but expanded its use during the pandemic. At hundreds of hospitals, including those in which we both work, a Deterioration Index score is prominently displayed on the chart of every patient admitted to the hospital.
The Deterioration Index is poised to upend a key cultural practice in medicine: triage. Loosely speaking, triage is an act of determining how sick a patient is at any given moment to prioritize treatment and limited resources. In the past, physicians have performed this task by rapidly interpreting a patient’s vital signs, physical exam findings, test results, and other data points, using heuristics learned through years of on-the-job medical training.
Ostensibly, the core assumption of the Deterioration Index is that traditional triage can be augmented, or perhaps replaced entirely, by machine learning and big data. Indeed, a study of 392 Covid-19 patients admitted to Michigan Medicine that the index was moderately successful at discriminating between low-risk patients and those who were at high-risk of being transferred to an ICU, getting placed on a ventilator, or dying while admitted to the hospital. But last year’s hurried rollout of the Deterioration Index also sets a worrisome precedent, and it illustrates the potential for such decision-support tools to propagate biases in medicine and change the ways in which doctors think about their patients.
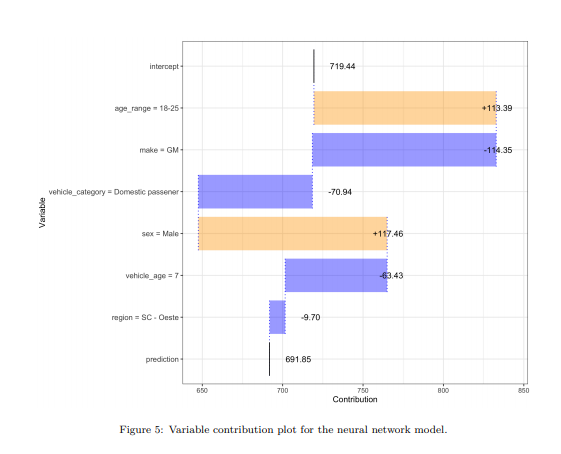
Machine learning methods have garnered increasing interest among actuaries in recent years. However, their adoption by practitioners has been limited, partly due to the lack of transparency of these methods, as compared to generalized linear models. In this paper, we discuss the need for model interpretability in property & casualty insurance ratemaking, propose a framework for explaining models, and present a case study to illustrate the framework.
The video features Neil Raden who is the author of ethical use of AI for Actuaries. Alongside him , it features Kevin Pledge who is CEO of Acceptiv , FSA,FIA and chair of Innovation and Research Committee of SOA. We discuss about the issue of ethics and about the use of new data sources in the recent Emerging issues in Underwriting Survey Report by IfOA.