Graphic:
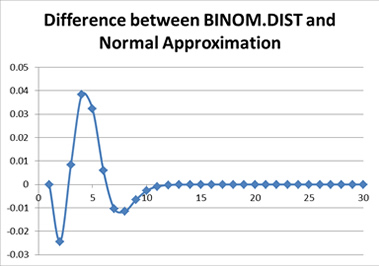
Excerpt:
Before we get into the different approaches, why should you care about knowing multiple ways to calculate a distribution when we have a perfectly good symbolic formula that tells us the probability exactly?
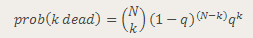
As we shall soon see, having that formula gives us the illusion that we have the “exact” answer. We actually have to calculate the elements within. If you try calculating the binomial coefficients up front, you will notice they get very large, just as those powers of q get very small. In a system using floating point arithmetic, as Excel does, we may run into trouble with either underflow or overflow. Obviously, I picked a situation that would create just such troubles, by picking a somewhat large number of people and a somewhat low probability of death.
I am making no assumptions as to the specific use of the full distribution being made. It may be that one is attempting to calculate Value at Risk or Conditional Tail Expectation values. It may be that one is constructing stress scenarios. Most of the places where the following approximations fail are areas that are not necessarily of concern to actuaries, in general. In the following I will look at how each approximation behaves, and why one might choose that approach compared to others.
Author(s): Mary Pat Campbell
Publication Date: January 2014
Publication Site: CompAct, SOA