Read the unreported cases of how Excel cases have been brought to court. This report finds that spreadsheet disputes have been central to 12 lawsuits brought in the US and UK over the past two years leading to $210 million in company losses. have been at the center of major procurement battles in court. The study has been carried out in consultation with Dr Simon Thorne, Senior Lecturer in Computing and Information Systems, Cardiff School of Technologies and programme chair of the European Spreadsheets Risks Interest Group (EuSpRIG).
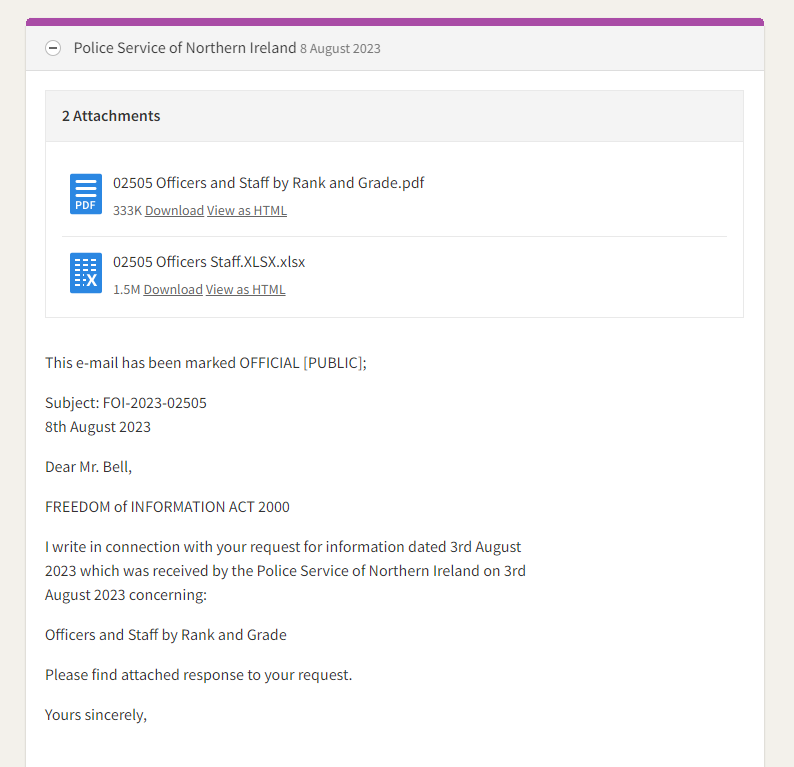
However, a second tab in the spreadsheet contained multiple entries in relation to more than 10,000 individuals. For each individual, there are 32 pieces of data meaning that in total, there are about 345,000 pieces of data in the file.
The spreadsheet, which has been seen by the Belfast Telegraph after we were alerted to it by a relative of a serving officer, includes each officer’s service number, their status, their gender, their contract type, their last name and initials, details of how much of the week they work, and their rank.
It also includes the location where they are based (but not their home address), their duty type (from chief constable to detective, intelligence officer and so on), details of their unit (such as the anti-corruption unit or the vetting department), their branch and department, and other technical information about their employment.
There are 10,799 entries in the database. There are 9,276 police officers and police staff. It is not clear if the additional entries relate to other employees or former employees.
The data has been removed from the internet.
There are details of staff who are suspended, on career breaks, or partly retired.
It reveals members of the organised crime unit, telecom liaison officers, intelligence officers stationed at ports and airports, PSNI pilots in its air support unit, officers in the surveillance unit and – of acute sensitivity – almost 40 PSNI staff based at MI5’s headquarters in Holywood.
There are a tiny number of individuals whose unit is given as “secret”. But although that does not disclose precisely what they do, it marks them out as operating in an acutely sensitive area – and then gives their name.
There are many books about spreadsheets out there. Most of these books will tell you things like “How to save a file” and “How to make a graph” and “How to compute the present value of a stream of cashflows” and “How to use conjoint analysis to figure out which features you should add to the next version of your company’s widgets in order to impress senior management and get a promotion and receive a pay raise so you can purchase a bigger boat than your neighbor has.”
This book isn’t about any of those. Instead, it’s about how to Think Spreadsheet. What does that mean? Well, spreadsheets lend themselves well to solving specific types of problems in specific types of ways. They lend themselves poorly to solving other specific types of problems in other specific types of ways.
Thinking Spreadsheet entails the following:
Understanding how spreadsheets work, what they do well, and what they don’t do well.
Using the spreadsheet’s structure to intelligently organize your data.
Solving problems using techniques that take advantage of the spreadsheet’s strengths.
Building spreadsheets that are easy to understand and difficult to break.
To help you learn how to Think Spreadsheet, I’ve collected a variety of curious and often whimsical examples. Some represent problems you are likely to encounter out in the wild, others problems you’ll never encounter outside of this book. Many of them we’ll solve multiple times. That’s because in each case, the means are more interesting than the ends. You’ll never (I hope) use a spreadsheet to compute all the prime numbers less than 100. But you’ll often (I hope) find useful the techniques we’ll use to compute those prime numbers, and if you’re clever you’ll go away and apply them to all sorts of real-world problems. As with most books of this sort, you’ll really learn the most if you recreate the examples yourself and play around with them, and I strongly encourage you to do so.
Author(s): Joel Grus
Publication Date: originally in dead-tree form 2010, accessed 29 Oct 2022
But in a court filing Monday, Jonathan Marks, the deputy elections secretary, acknowledged that a fourth county, Butler, had also refused to count those ballots — and that the county had notified the department three weeks before the lawsuit was filed.
Marks apologized to the court for what he described as an oversight resulting from “a manual process” — a spreadsheet — the department had used to track which counties were counting undated ballots. Butler County was misclassified in the spreadsheet, he said, and from that point forward was left out of the state’s campaign to push counties that hadn’t included them.
The Bank of England has fined Standard Chartered £46.5m for repeatedly misreporting its liquidity position and for “failing to be open and cooperative” with the regulator.
The Bank’s Prudential Regulation Authority (PRA) said Standard Chartered had made five errors in reporting an important liquidity metric between March 2018 and May 2019, which meant the watchdog did not have a reliable overview of the bank’s US dollar liquidity position.
…..
One of the errors occurred in November 2018, as a result of a mistake in a spreadsheet entry. A positive amount was included when a zero or negative value was expected, leading to an $7.9bn (£6bn) over-reporting of the bank’s dollar liquidity position.
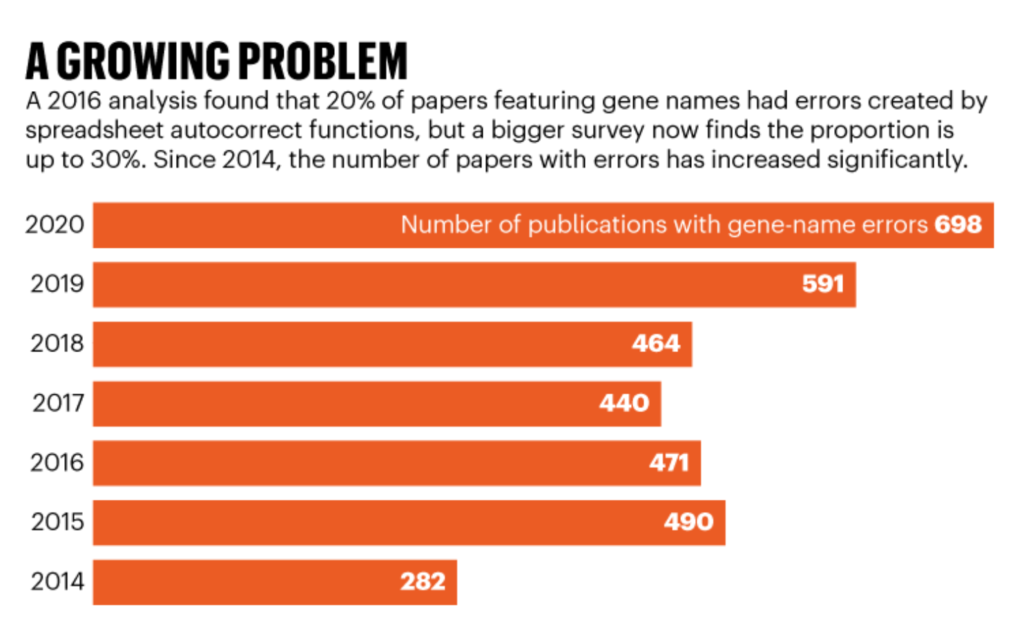
In 2016, Mark Ziemann and his colleagues at the Baker IDI Heart and Diabetes Institute in Melbourne, Australia, quantified the problem. They found that one-fifth of papers in top genomics journals contained gene-name conversion errors in Excel spreadsheets published as supplementary data2. These data sets are frequently accessed and used by other geneticists, so errors can perpetuate and distort further analyses.
However, despite the issue being brought to the attention of researchers — and steps being taken to fix it — the problem is still rife, according to an updated and larger analysis led by Ziemann, now at Deakin University in Geelong, Australia3. His team found that almost one-third of more than 11,000 articles with supplementary Excel gene lists published between 2014 and 2020 contained gene-name errors (see ‘A growing problem’).
Simple checks can detect autocorrect errors, says Ziemann, who researches computational reproducibility in genetics. But without those checks, the errors can easily go unnoticed because of the volume of data in spreadsheets.
Have you ever built a perfect financial model without any errors? Thought not! And for that reason, all good modellers know they need to include some error checks. But what is not as clear is how many error checks you should have, when you should include them and what form they should take. Excel “helpfully” provided us with functions like ISERR, ISERROR and IFERROR but as you progress your modelling journey you should learn to avoid these functions. Plus, you also learn the sad truth that Excel can’t even do basic maths sometimes! Join us to hear from financial modelling specialist Andrew Berg, who has spent years building models, and so happily admits he has probably already made most of the mistakes you haven’t yet had a chance to! The good news is that he is willing to share the tips he has learned about the right types of error checks to add to your models so you don’t have to learn the hard way. ★Download the resources here ► https://plumsolutions.com.au/virtual-… ★Register for more meetups like this ► https://plumsolutions.com.au/meetup/ ★Connect with Andrew on Linkedin ► https://www.linkedin.com/in/andrew-be…
When the Defense Information Systems Agency sought a new satellite services acquisition on behalf of the Navy, it included a spreadsheet so bidders could fill in their prices. But the spreadsheet included the prices from the current contract, which were supposed to be inaccessible. For how things turned out, Smith Pachter McWhorter procurement attorney Joe Petrillo joined Federal Drive with Tom Temin.
…..
Joe Petrillo: Sure. This is another excel spreadsheet disaster, and we talked about one a few weeks ago. It involved an acquisition of satellite telecom services for the Navy’s Military Sealift Command. It was an acquisition of commercial satellite telecommunications services. And they were divided into both bandwidth and non-bandwidth services. And the contract would be able to run to for up to 10 years in duration. Part of the contract, as you said, was an excel spreadsheet of the various different line items with blanks for offers to include their price. Unfortunately, this spreadsheet had hidden tabs, 19 hidden tabs, and those included, among other things, historical pricing information from the current contract. So Inmarsat, which was the incumbent contractor, holding that contract, notified the government and said, look you’ve disclosed our pricing information, do something about it. So the government deleted the offending spreadsheet from the SAM.gov website. But they understood and this was the case, third party aggregators had already downloaded it, and it was out there, it was available.
Somewhere in PHE’s data pipeline, someone had used the wrong Excel file format, XLS rather than the more recent XLSX. And XLS spreadsheets simply don’t have that many rows: 2 to the power of 16, about 64,000. This meant that during some automated process, cases had vanished off the bottom of the spreadsheet, and nobody had noticed.
The idea of simply running out of space to put the numbers was darkly amusing. A few weeks after the data-loss scandal, I found myself able to ask Bill Gates himself about what had happened. Gates no longer runs Microsoft, and I was interviewing him about vaccines for a BBC program called How to Vaccinate The World. But the opportunity to have a bit of fun quizzing him about XLS and XLSX was too good to pass up.
I expressed the question in the nerdiest way possible, and Gates’s response was so strait-laced I had to smile: “I guess… they overran the 64,000 limit, which is not there in the new format, so…” Well, indeed. Gates then added, “It’s good to have people double-check things, and I’m sorry that happened.”
Exactly how the outdated XLS format came to be used is unclear. PHE sent me an explanation, but it was rather vague. I didn’t understand it, so I showed it to some members of Eusprig, the European Spreadsheet Risks Group. They spend their lives analyzing what happens when spreadsheets go rogue. They’re my kind of people. But they didn’t understand what PHE had told me, either. It was all a little light on detail.