Graphic:
Excerpt:
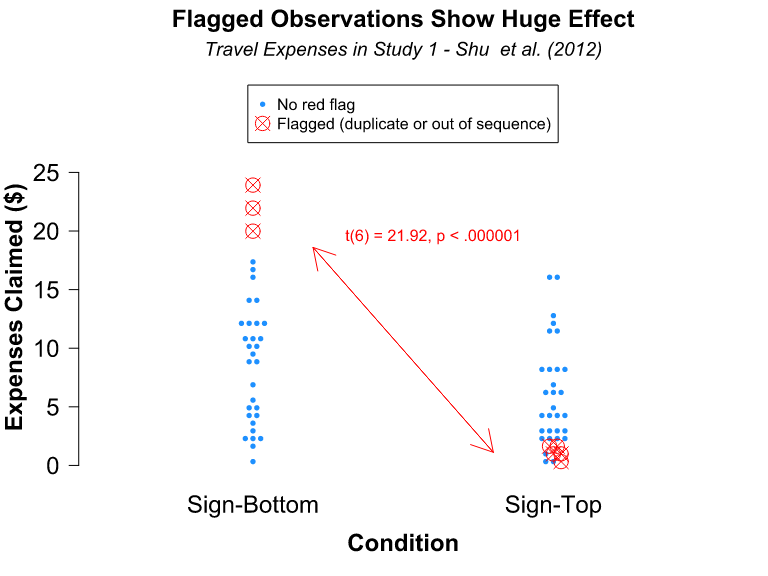
I was reminded of this student’s clever ploy when Frederik Joelving, a journalist with Retraction Watch, recently contacted me about a published paper written by two prominent economists, Almas Heshmati and Mike Tsionas, on green innovations in 27 countries during the years 1990 through 2018. Joelving had been contacted by a PhD student who had been working with the same data used by Heshmati and Tsionas. The student knew the data in the article had large gaps and was “dumbstruck” by the paper’s assertion these data came from a “balanced panel.” Panel data are cross-sectional data for, say, individuals, businesses, or countries at different points in time. A “balanced panel” has complete cross-section data at every point in time; an unbalanced panel has missing observations. This student knew firsthand there were lots of missing observations in these data.
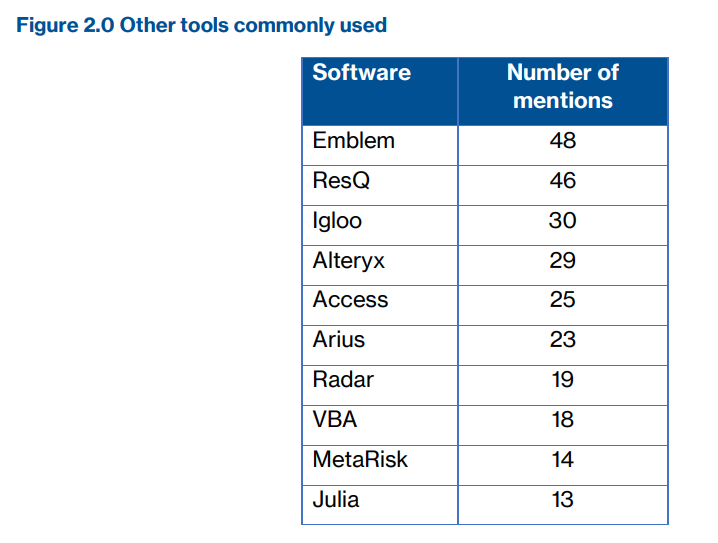
The student contacted Heshmati and eventually obtained spreadsheets of the data he had used in the paper. Heshmati acknowledged that, although he and his coauthor had not mentioned this fact in the paper, the data had gaps. He revealed in an email that these gaps had been filled by using Excel’s autofill function: “We used (forward and) backward trend imputations to replace the few missing unit values….using 2, 3, or 4 observed units before or after the missing units.”
That statement is striking for two reasons. First, far from being a “few” missing values, nearly 2,000 observations for the 19 variables that appear in their paper are missing (13% of the data set). Second, the flexibility of using two, three, or four adjacent values is concerning. Joelving played around with Excel’s autofill function and found that changing the number of adjacent units had a large effect on the estimates of missing values.
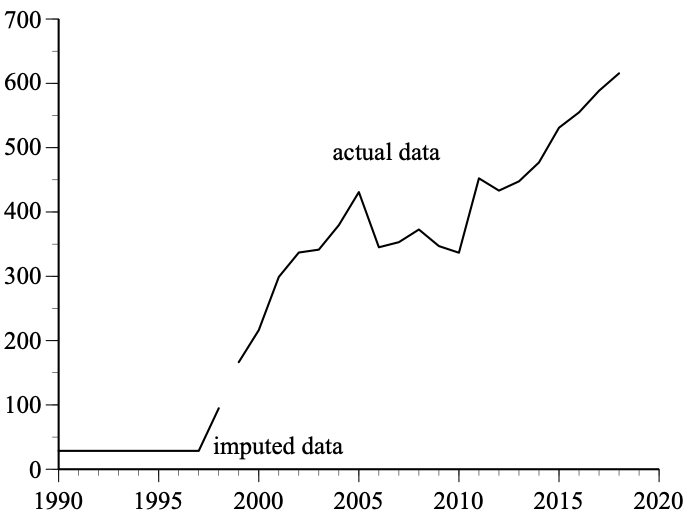
Joelving also found that Excel’s autofill function sometimes generated negative values, which were, in theory, impossible for some data. For example, Korea is missing R&Dinv (green R&D investments) data for 1990-1998. Heshmati and Tsionas used Excel’s autofill with three years of data (1999, 2000, and 2001) to create data for the nine missing years. The imputed values for 1990-1996 were negative, so the authors set these equal to the positive 1997 value.
Author(s): Gary Smith
Publication Date: 21 Feb 2024
Publication Site: Retraction Watch