Link: https://papers.nips.cc/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf
Graphic:
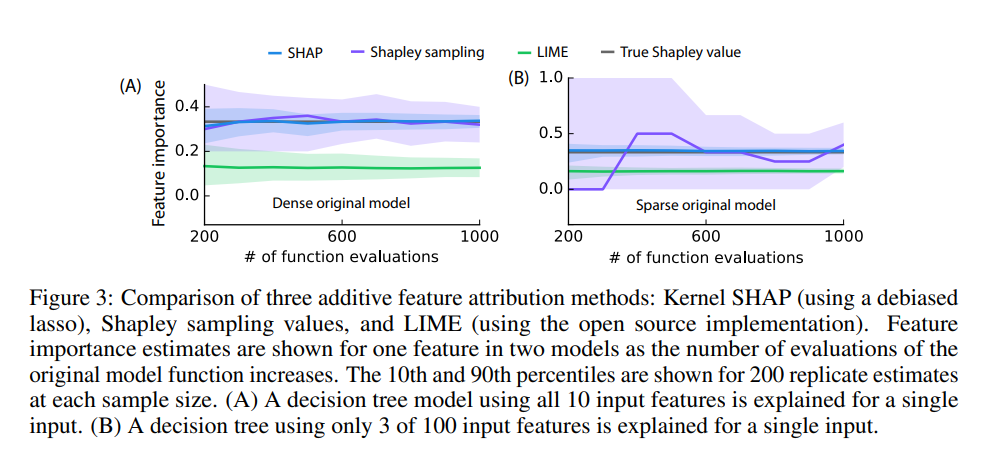
Excerpt:
Understanding why a model makes a certain prediction can be as crucial as the
prediction’s accuracy in many applications. However, the highest accuracy for large
modern datasets is often achieved by complex models that even experts struggle to
interpret, such as ensemble or deep learning models, creating a tension between
accuracy and interpretability. In response, various methods have recently been
proposed to help users interpret the predictions of complex models, but it is often
unclear how these methods are related and when one method is preferable over
another. To address this problem, we present a unified framework for interpreting
predictions, SHAP (SHapley Additive exPlanations). SHAP assigns each feature
an importance value for a particular prediction. Its novel components include: (1)
the identification of a new class of additive feature importance measures, and (2)
theoretical results showing there is a unique solution in this class with a set of
desirable properties. The new class unifies six existing methods, notable because
several recent methods in the class lack the proposed desirable properties. Based
on insights from this unification, we present new methods that show improved
computational performance and/or better consistency with human intuition than
previous approaches.
Author(s): Scott M. Lundberg, Su-In Lee
Publication Date: 2017
Publication Site: Conference on Neural Information Processing Systems